/ Mini-Labs / Drift: cómo envejecen los modelos
Drift: cómo envejecen los modelos
Qué pasa cuando los datos de producción ya no se parecen a los de entrenamiento — y cómo detectarlo antes de que el daño sea invisible.
ContextoEl fallo que no genera ningún error
El drift es el problema más silencioso en ML en producción: el modelo no falla, el pipeline no lanza excepciones, y las métricas internas no cambian. Simplemente, el mundo cambió y el modelo no lo sabe.
- Los datos de producción se alejan gradualmente de los de entrenamiento — sin aviso, sin excepción, sin alerta automática.
- El modelo sigue haciendo predicciones con la misma confianza de siempre, incluso cuando esa confianza ya no tiene respaldo real.
- La degradación es acumulativa: cada semana el modelo es un poco peor, hasta que el problema ya es demasiado grande para ignorarse.
- El drift puede venir de una sola variable — si esa variable es la más importante del modelo, el impacto en métricas es directo y desproporcionado.
- Sin un sistema de monitoreo externo que compare distribuciones, el drift es indetectable desde dentro del pipeline.
- Detectarlo a tiempo no requiere reentrenar — solo requiere saber dónde mirar y con qué herramienta estadística.
DatosVisualizar el drift antes de medir
El primer paso para entender drift es verlo. Antes de cualquier test estadístico, comparar las distribuciones de referencia y producción revela si algo cambió y en qué dirección.
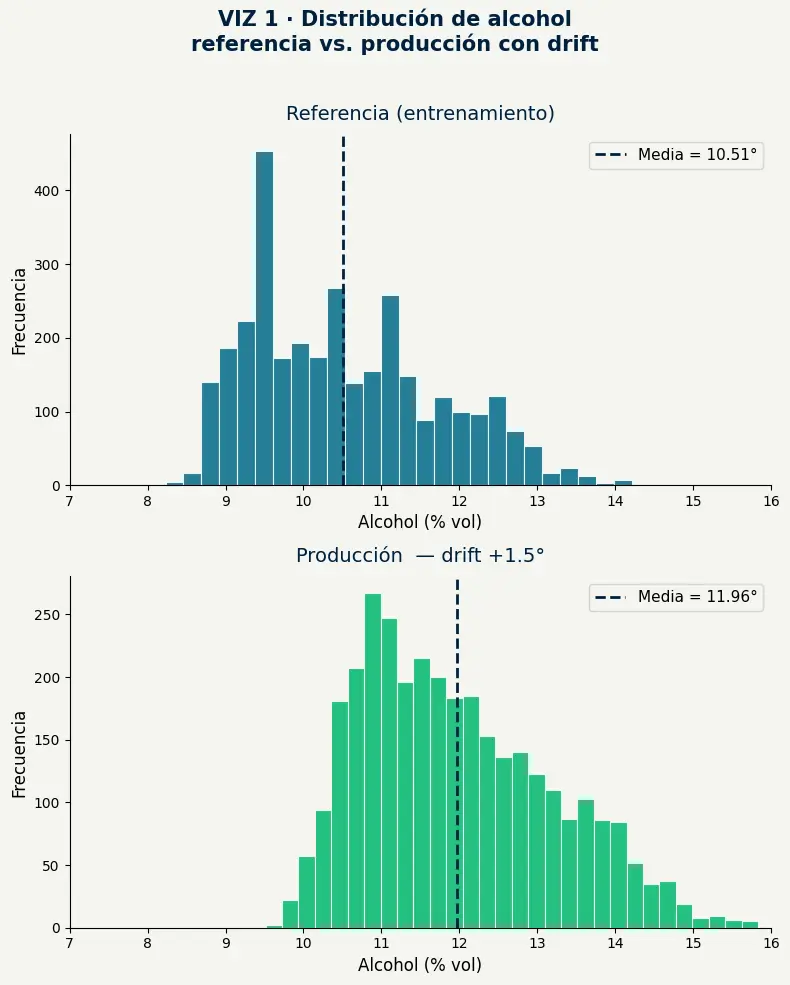
- La distribución de referencia tiene media 10.51° — el modelo aprendió a predecir calidad sobre vinos con ese perfil de alcohol.
- La distribución de producción tiene media 11.96° — un desplazamiento de 1.5° que parece pequeño y es estadísticamente enorme.
- El modelo no recibe ninguna señal de que los datos que está procesando son distintos a los que lo entrenaron. Sigue respondiendo como si todo fuera igual.
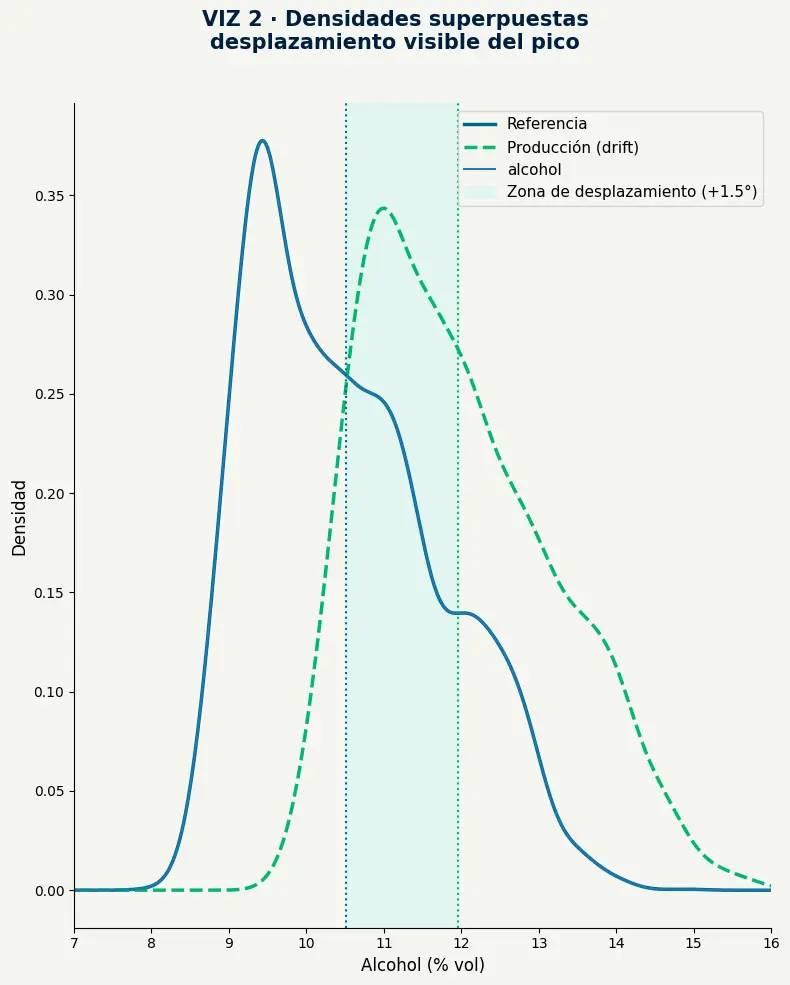
- Superponer las distribuciones hace evidente lo que los histogramas por separado pueden esconder: el pico de producción cae fuera del rango central de referencia.
- La zona sombreada entre las dos distribuciones representa el espacio donde el modelo opera sin datos de entrenamiento que lo respalden.
- Cuanto mayor es el área de desplazamiento sin solapamiento, mayor es el riesgo de degradación en métricas operativas.
DetecciónKolmogorov-Smirnov: cuantificar lo que ves
Ver el drift visualmente no es suficiente para tomar decisiones. El test KS convierte la diferencia entre distribuciones en un número con significancia estadística — y permite priorizar qué features requieren atención.
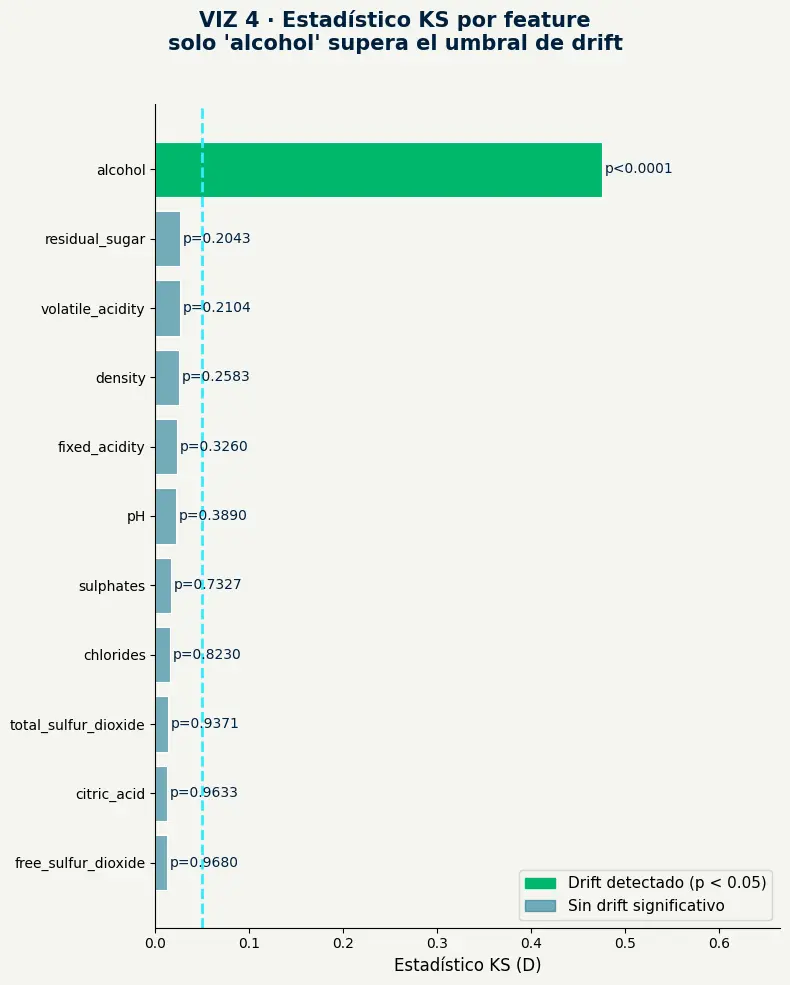
alcohol supera el umbral de drift.
alcoholobtiene D = 0.475 con p < 0.0001 — el único feature de los 11 analizados que supera el umbral de significancia.- Las 10 variables restantes tienen p-values entre 0.20 y 0.97 — ninguna muestra drift estadísticamente relevante en este escenario.
- Identificar el feature específico que drifteó permite actuar de forma quirúrgica: no es necesario reentrenar todo el modelo si solo una variable cambió.
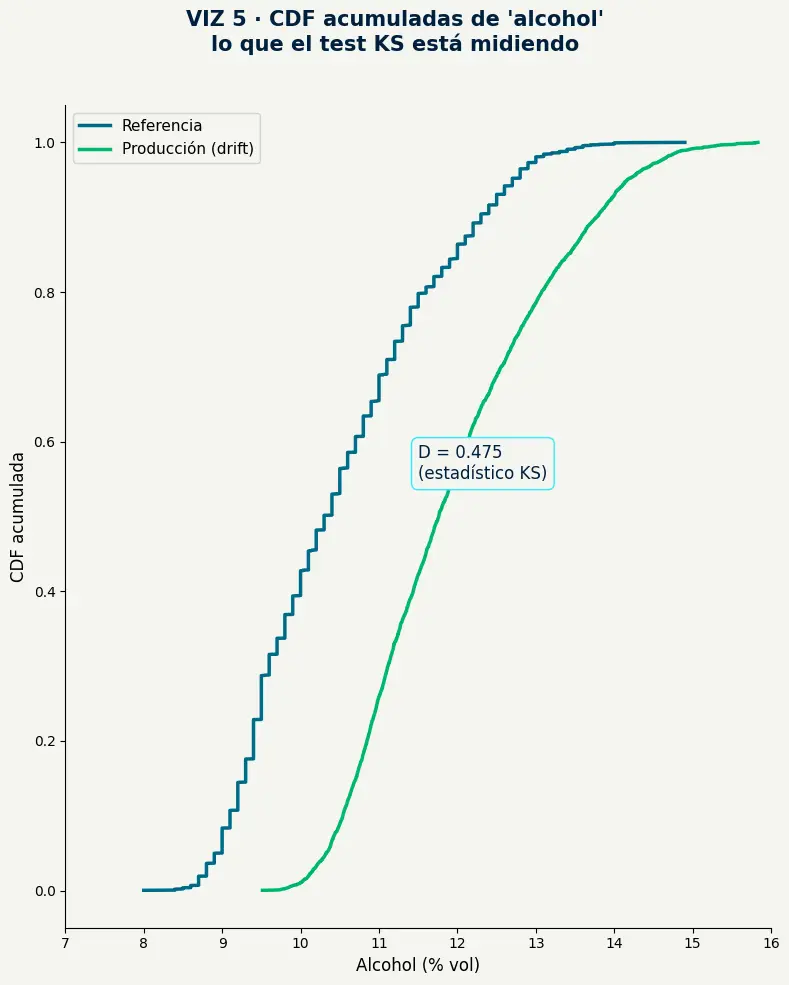
alcohol — lo que el test KS está midiendo.
- El test KS mide la distancia máxima entre las dos funciones de distribución acumulada — ese hueco visible entre las curvas es exactamente D = 0.475.
- Una D cercana a 0 indica distribuciones casi idénticas. Una D de 0.475 en una escala de 0 a 1 confirma que la diferencia no es ruido.
- La CDF es más informativa que el histograma para comparar distribuciones: muestra la acumulación en cada punto del rango, sin depender del tamaño del bin.
ModeloPor qué este drift golpea donde más duele
No todos los drifts tienen el mismo impacto. El daño depende directamente de la importancia que el feature afectado tiene en el modelo — y en este caso, el feature que drifteó es el más crítico.
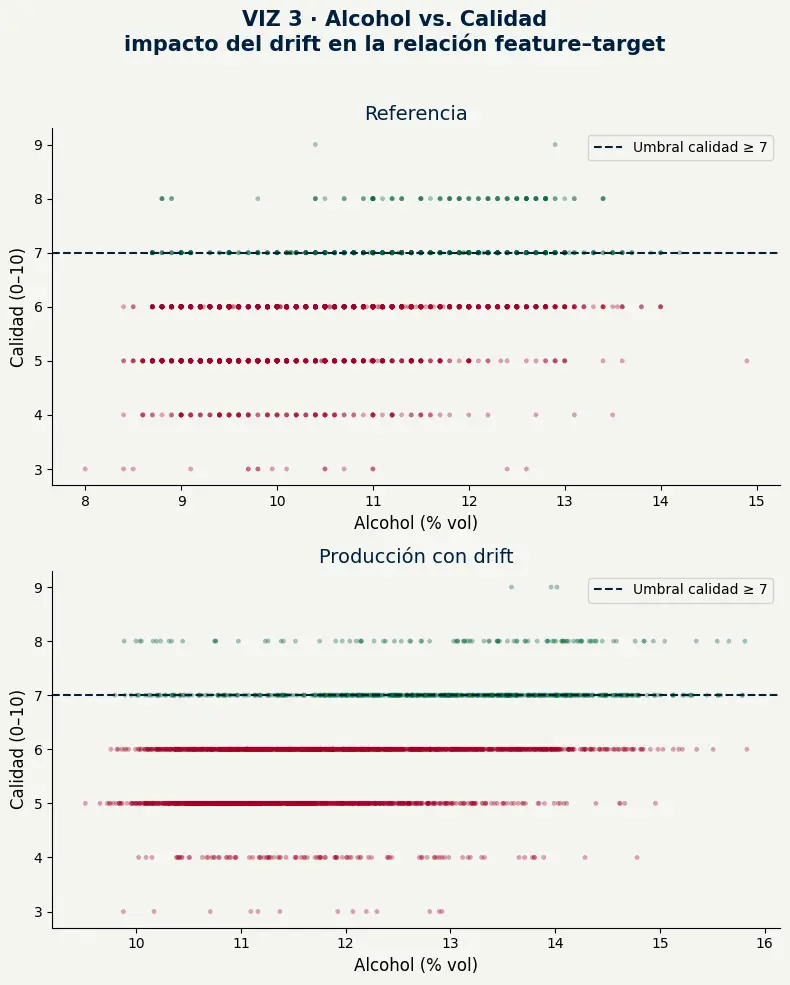
- En referencia, el modelo aprendió que niveles de alcohol entre 9° y 13° se asocian con distintas bandas de calidad — una relación clara que usó para aprender.
- En producción con drift, ese mismo rango ya no representa lo mismo: los vinos con alcohol en 11-13° ahora son el segmento medio, no el alto.
- El modelo aplica las mismas reglas internas sobre un espacio de datos desplazado — no falla, pero sus predicciones son cada vez menos precisas.
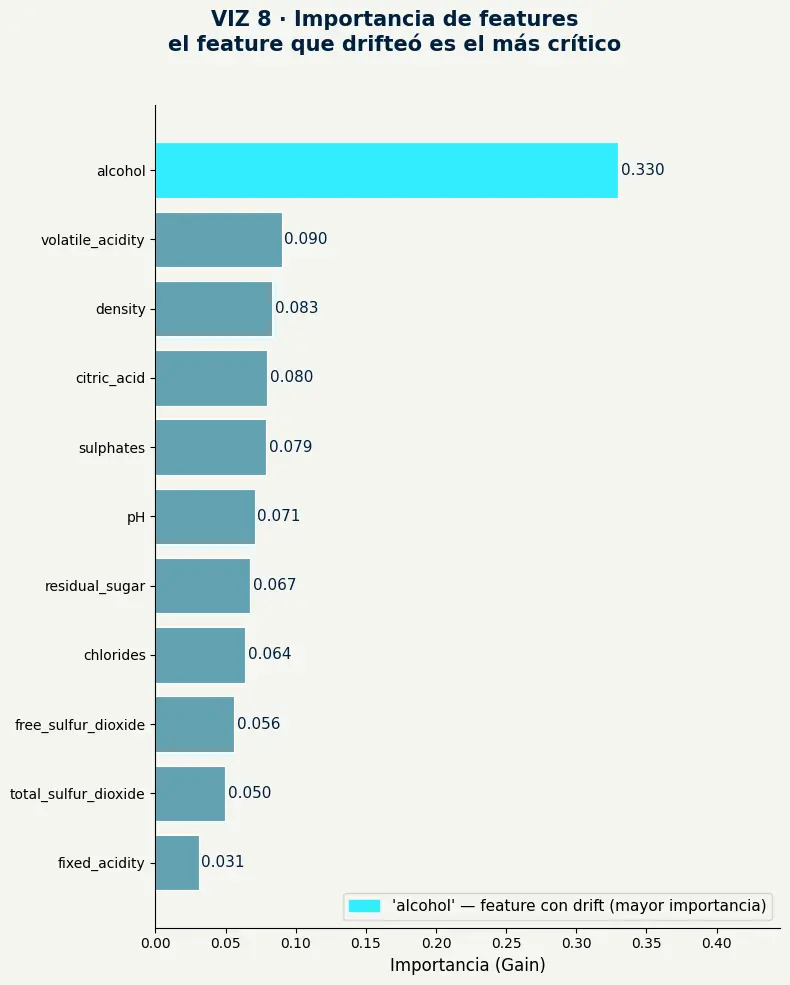
alcoholtiene importancia 0.330 — más del triple que el segundo feature más relevante (volatile_aciditycon 0.090).- El drift no golpeó al azar: afectó exactamente la variable sobre la que el modelo más depende para generar sus predicciones.
- Cuando el feature más crítico cambia de distribución, la degradación en métricas operativas es directa y proporcional a su peso en el modelo.
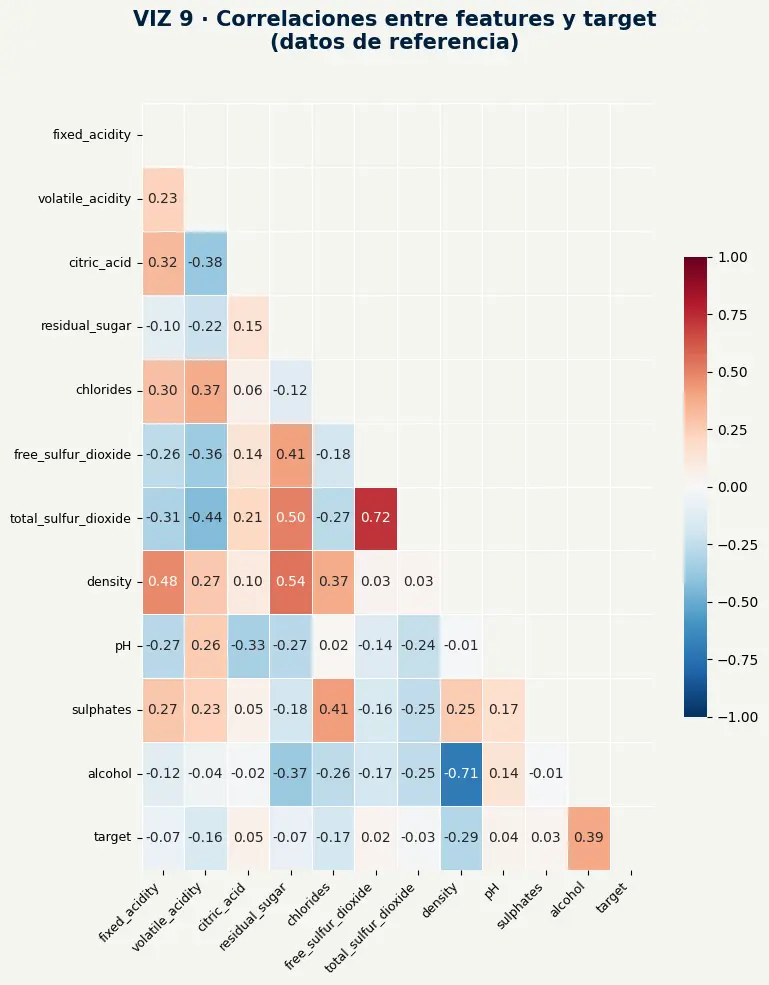
alcoholtiene la correlación más alta con el target (0.39) — lo que confirma que es la variable con más señal predictiva en el dataset.densityyalcoholtienen correlación negativa fuerte (-0.71) entre sí, pero soloalcoholdrifteó — no toda la estructura de correlaciones se vio afectada.- Conocer el mapa de correlaciones antes del despliegue permite anticipar cuáles features, si driftan, tendrán mayor impacto en la calidad de las predicciones.
ResultadosCuánto pierde el modelo cuando hay drift
Mismo modelo, mismo código, mismos hiperparámetros. La única diferencia entre los escenarios es la distribución de los datos de entrada.
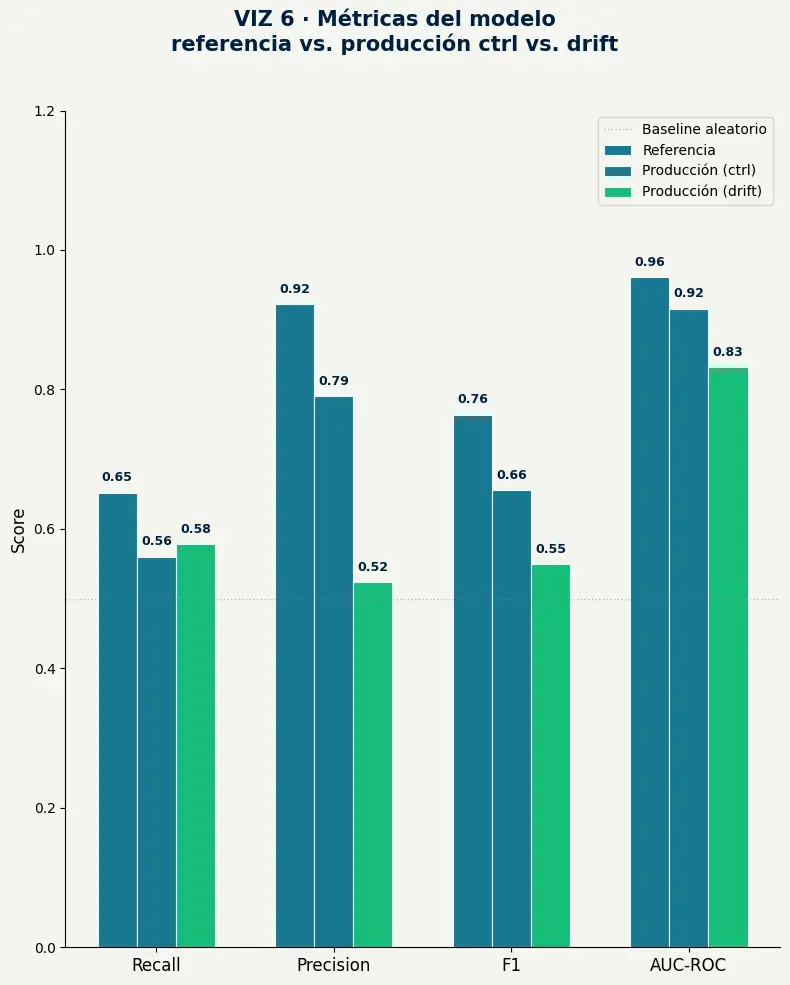
- AUC-ROC baja de 0.96 (referencia) a 0.83 (drift) — una caída de 13 puntos en la métrica más robusta de clasificación binaria.
- F1 baja de 0.76 a 0.55 y Precision de 0.92 a 0.52 — en producción con drift, el modelo acerca sus números al baseline aleatorio.
- La degradación no es un colapso sino una erosión gradual: el modelo sigue "funcionando", pero cada predicción tiene menos respaldo real detrás.
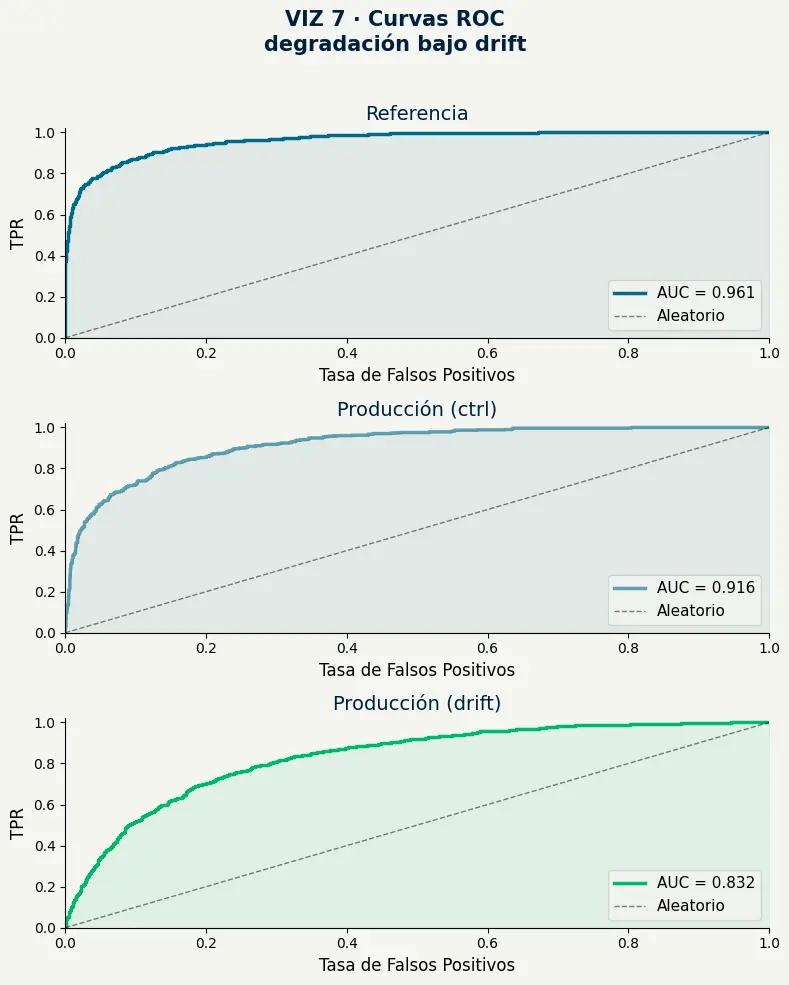
- La curva de referencia (AUC 0.961) abraza la esquina superior izquierda — el comportamiento esperado de un modelo bien calibrado sobre sus propios datos.
- La curva con drift (AUC 0.832) se aleja visiblemente de esa esquina — el área bajo la curva que se pierde representa predicciones que ya no discriminan correctamente.
- La diferencia entre producción ctrl (AUC 0.916) y drift (AUC 0.832) aísla el impacto exclusivo del desplazamiento de distribución: 0.084 puntos de AUC por una sola variable.
CódigoRepositorio del experimento
El notebook completo incluye la simulación de drift, el pipeline de detección con KS, la comparación de métricas en los tres escenarios y las 9 visualizaciones.
- Dataset: Wine Quality — UCI ML Repository — público, sin registro. Vino tinto con 11 features fisicoquímicos y calidad evaluada por sommeliers (0–10).
- Drift simulado: desplazamiento gaussiano de +1.5° en la variable
alcoholsobre el conjunto de producción. - Detección: test Kolmogorov-Smirnov aplicado a los 11 features, con umbral de significancia p < 0.05.
- Modelos: Random Forest con los mismos hiperparámetros en los tres escenarios — referencia, producción ctrl y producción con drift.
- Visualizaciones: histogramas comparativos, densidades superpuestas, scatter feature-target, estadístico KS por feature, CDFs acumuladas, métricas comparativas, curvas ROC, importancia de features y mapa de correlaciones.