/ Mini-Labs / Granularidades: el error que arruina el modelo
Granularidades: el error que arruina el modelo
Qué pasa cuando el dataset mezcla observaciones de distintos niveles de análisis — y cómo detectarlo antes de escribir una sola línea de modelo.
ContextoEl accuracy del 85% que no aprendió nada
La granularidad mixta es el problema más invisible en la preparación de datos: el modelo no falla, las métricas parecen sólidas, y nadie sospecha que el dataset está contaminado con observaciones del nivel equivocado.
- El dataset mezcla filas de distintos niveles de análisis — líneas de producto dentro de pedidos — y el target se define donde no corresponde.
- El modelo reporta un accuracy del 85% y no ha aprendido nada útil: memorizó los pedidos grandes que aparecen 50 veces en el conjunto de entrenamiento.
- La degradación es estructural desde el origen: cada pedido grande contamina el entrenamiento multiplicando su influencia por el número de líneas que contiene.
- El error puede venir de una sola decisión de diseño — definir el target a nivel de línea cuando la pregunta del negocio es a nivel de pedido.
- Sin una inspección explícita de la distribución de filas por unidad, la granularidad mixta es indetectable desde las métricas de validación cruzada.
- Detectarlo no requiere más datos ni un algoritmo distinto — solo una pregunta: ¿cuál es la unidad de análisis real de mi problema?
DatosVisualizar la granularidad antes de modelar
El primer paso para entender granularidad mixta es verla. Antes de definir cualquier target, inspeccionar la distribución de filas por unidad revela si hay un problema de nivel de análisis — y en qué magnitud.
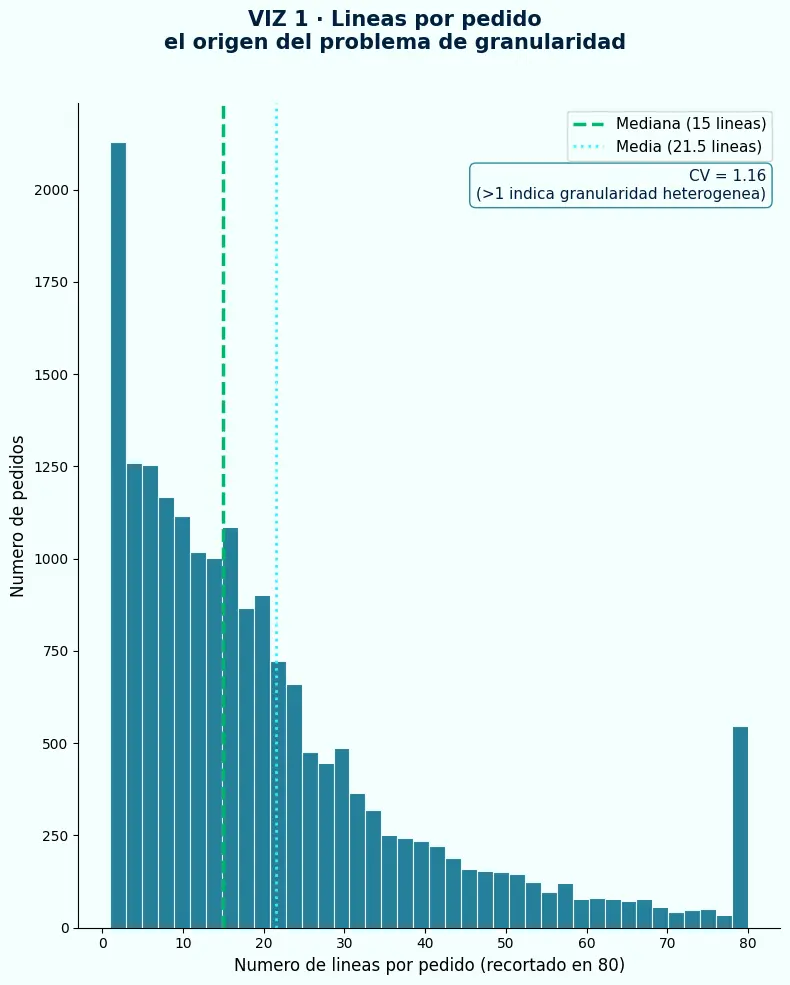
- La distribución de líneas por pedido va de 1 a más de 80 — un rango que indica granularidad altamente heterogénea dentro del dataset.
- El coeficiente de variación (CV) supera 1.0 — la señal estadística más directa de que distintos pedidos tienen peso radicalmente diferente si se modela a nivel de línea.
- Un pedido con 80 líneas contribuye 80 veces al entrenamiento. El modelo no aprende características del cliente — aprende a reconocer ese pedido.
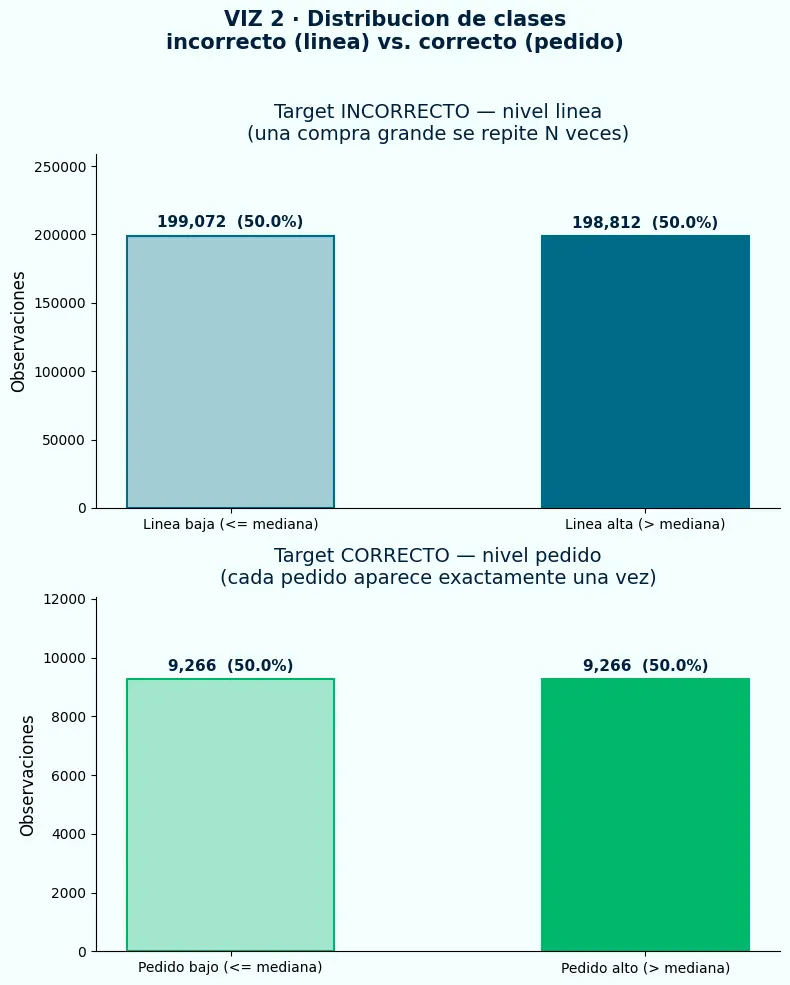
- El target a nivel de línea genera 541,909 observaciones — cada pedido grande se replica decenas de veces, inflando artificialmente el dataset de entrenamiento.
- El target a nivel de pedido genera una fracción de esas observaciones — cada pedido aparece exactamente una vez, sin inflación por repetición.
- Ambas distribuciones de clases parecen balanceadas, lo que hace invisible el problema desde las métricas superficiales de balance de clases.
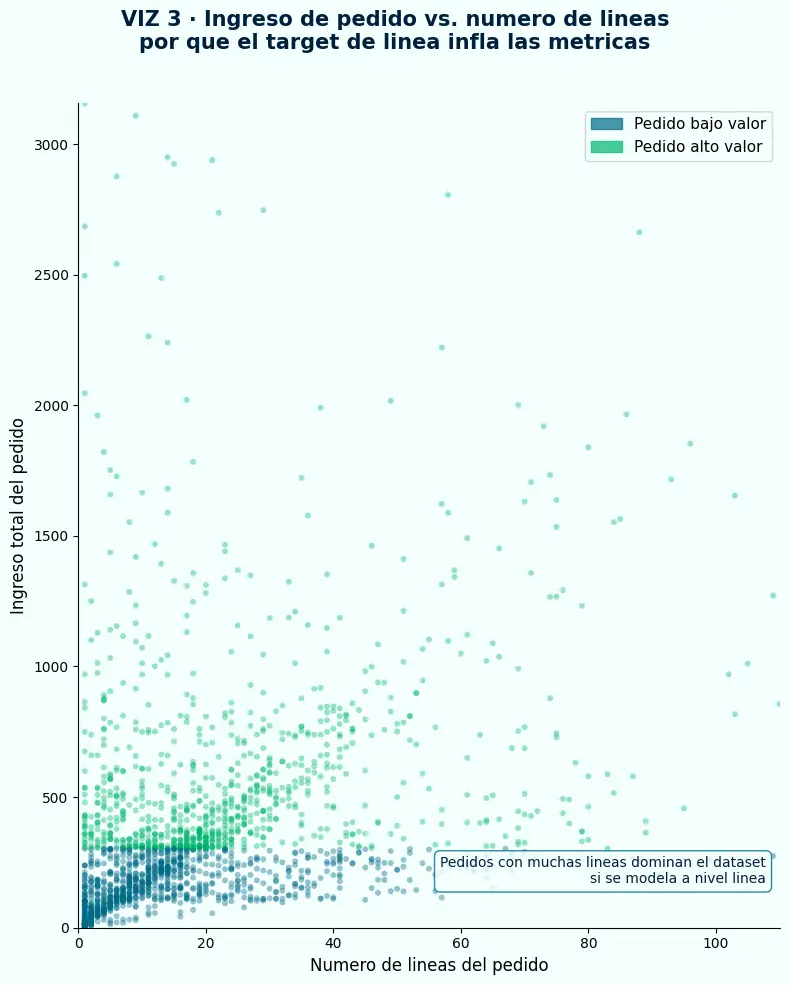
- Los pedidos de alto valor tienden a tener más líneas — una correlación real que el modelo explota cuando el target es a nivel de línea.
- En el espacio de líneas, cada punto de alta densidad representa un solo pedido grande repitiendo su señal decenas de veces al modelo.
- Cuando el target está a nivel de pedido, esa correlación trivial desaparece: el modelo tiene que aprender características reales de clientes y contextos de compra.
DetecciónTres señales que confirman granularidad mixta
Ver el problema visualmente no es suficiente para tomar decisiones. Hay tres diagnósticos cuantitativos que convierten la sospecha de granularidad mixta en evidencia accionable.
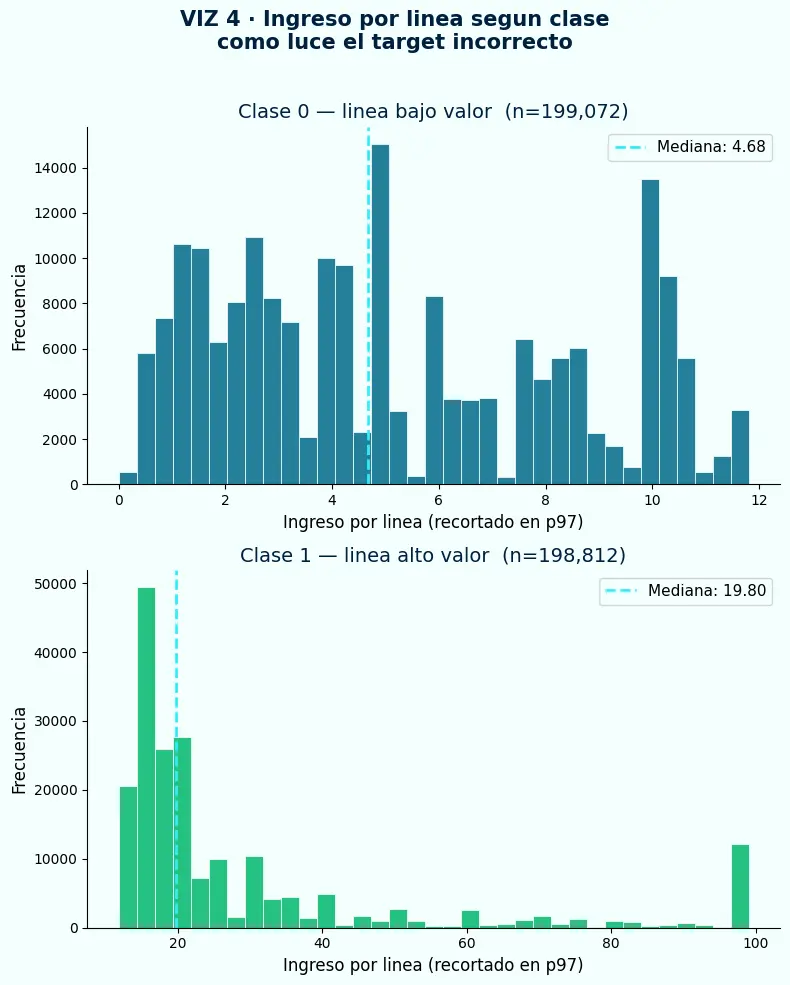
- La clase 1 del target de línea agrupa las líneas con ingreso por encima de la mediana — una separación que parece limpia pero mezcla líneas de pedidos de muy distinto tamaño.
- Una línea de alto ingreso en un pedido de 2 líneas y una línea de alto ingreso en un pedido de 60 líneas reciben el mismo peso en el entrenamiento — cuando no deberían.
- El modelo aprende el atajo: los pedidos grandes generan más líneas de alto ingreso, y esos pedidos se repiten muchas veces. La separación de clases es real pero no útil.
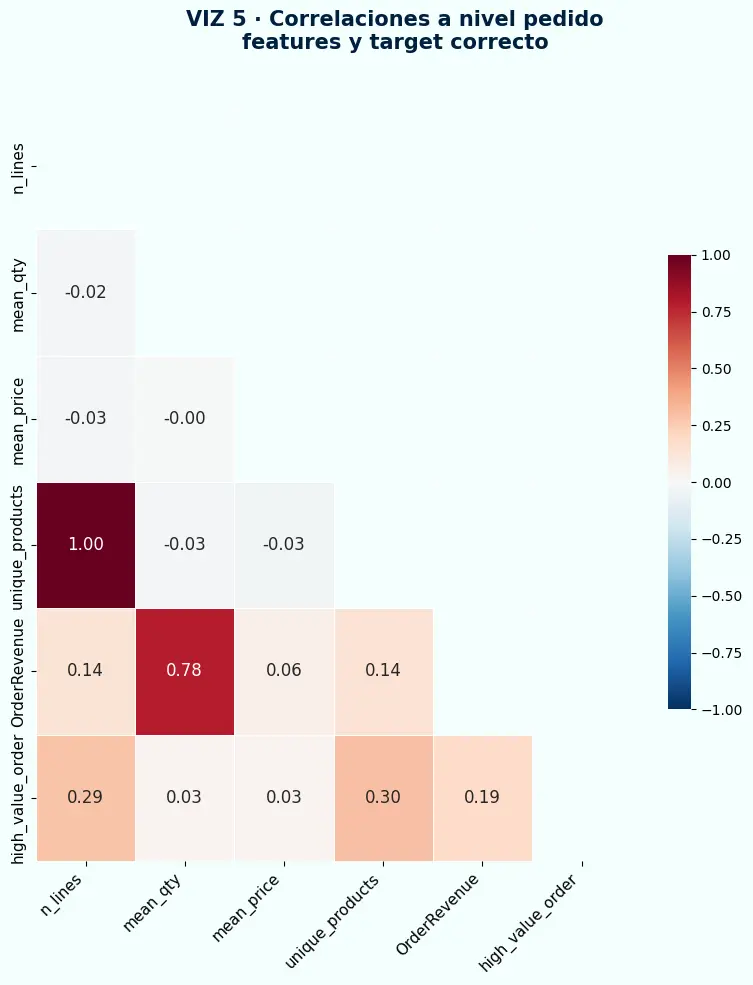
n_linestiene correlación alta conOrderRevenue— lo que confirma que el número de líneas es un proxy del valor del pedido, no una causa.unique_productsymean_pricemuestran correlaciones moderadas con el target correcto — señales reales del comportamiento del cliente que el modelo debería aprender.- Conocer el mapa de correlaciones antes de fijar el target permite anticipar qué features, si se usan con la granularidad equivocada, generarán atajos de memorización.
ModeloPor qué esta granularidad engaña exactamente donde más duele
No todos los errores de granularidad tienen el mismo impacto. El daño depende directamente de la correlación entre el número de filas por unidad y el target — y en datasets transaccionales, esa correlación es siempre alta.
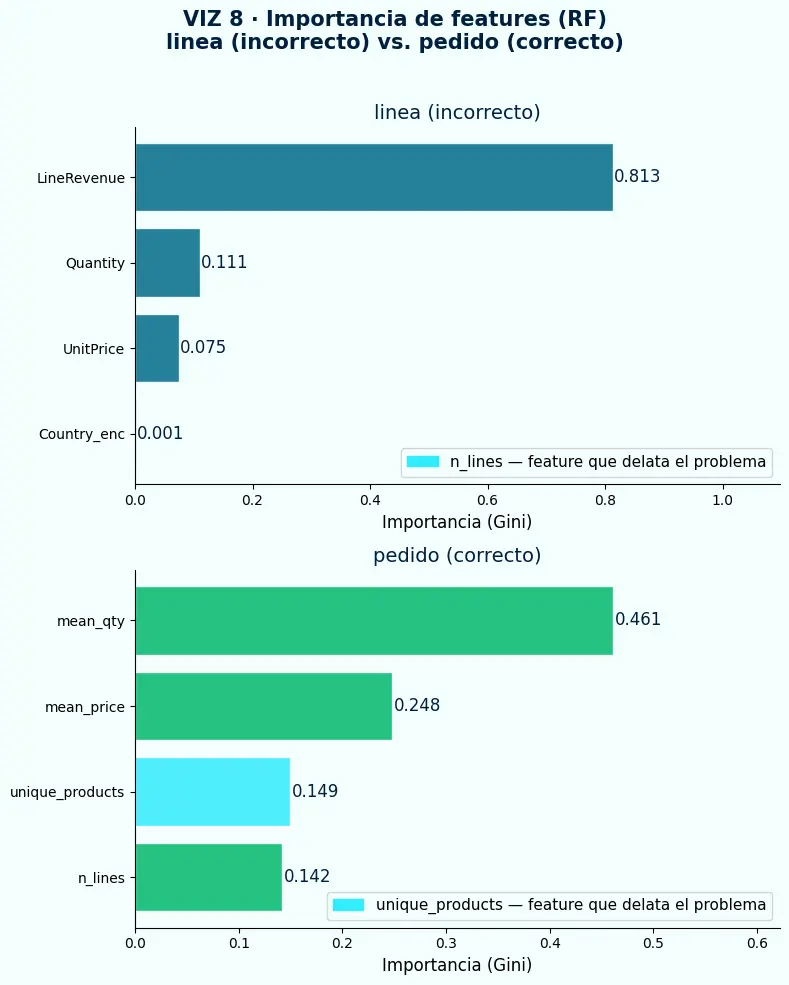
- Con el target de línea (incorrecto),
LineRevenuedomina la importancia — el modelo aprendió que las líneas con ingreso alto predicen la clase alta, una tautología circular. - Con el target de pedido (correcto),
unique_productsymean_priceemergen como relevantes — características reales del comportamiento del cliente en esa sesión de compra. - La diferencia en la distribución de importancias entre ambos modelos es la señal más clara de que el target incorrecto generó aprendizaje artificial, no estructural.
ResultadosCuánto miente el modelo cuando hay granularidad mixta
Mismo modelo, mismo código, mismos hiperparámetros. La única diferencia entre los escenarios es el nivel de análisis en el que se define el target.
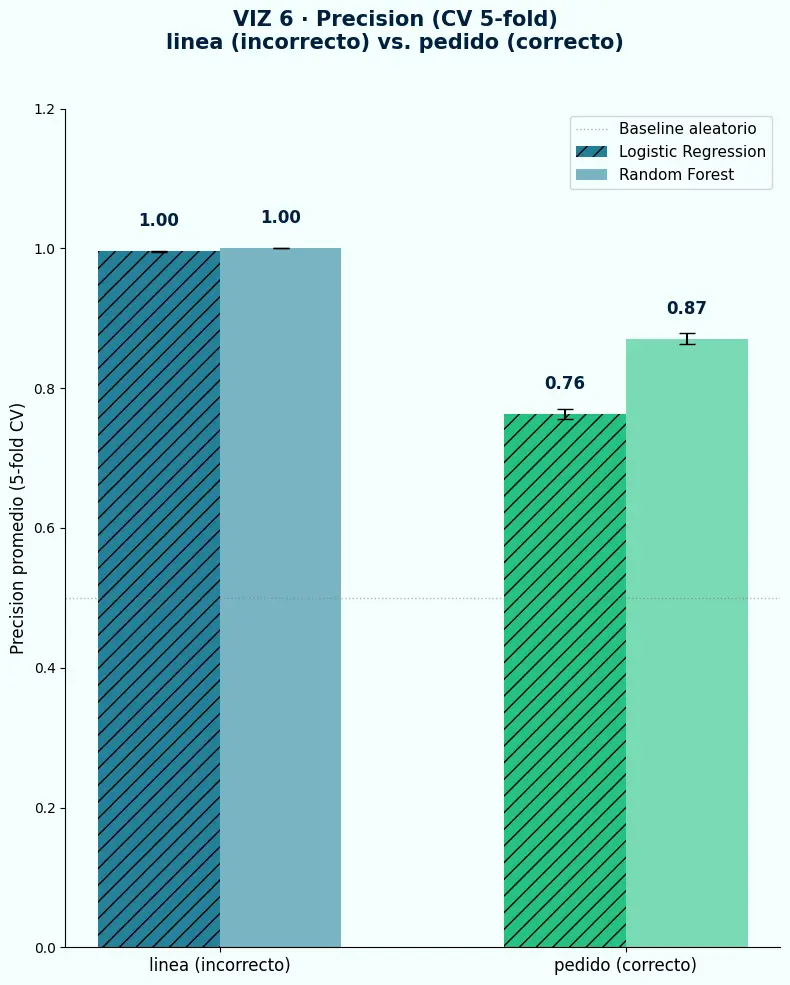
- La Precision con el target de línea es alta — no porque el modelo haya aprendido algo útil, sino porque memorizó los pedidos grandes que aparecen repetidos en el entrenamiento.
- Cuando se corrige la granularidad y se modela a nivel de pedido, las métricas reflejan el aprendizaje real: más difícil, menos inflado, genuinamente transferible a producción.
- La caída en Precision al corregir la granularidad no es una señal de mal modelo — es la señal de que el modelo anterior no estaba aprendiendo lo que creíamos.
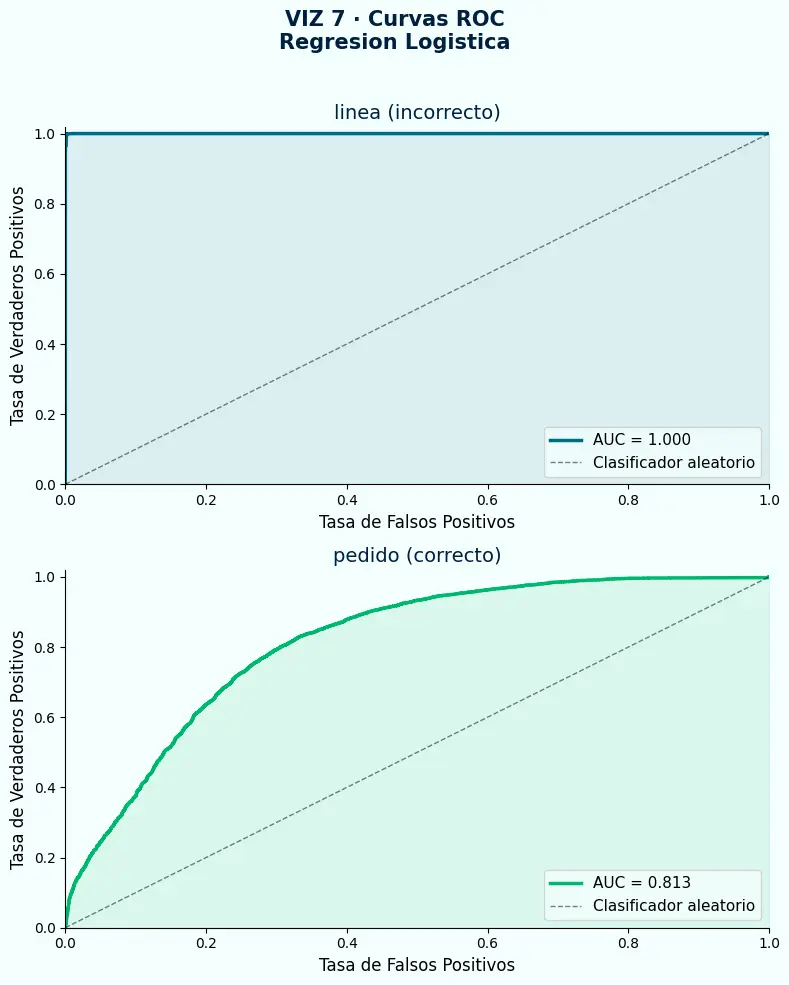
- La curva ROC con el target de línea muestra un AUC aparentemente bueno — construido sobre repetición de patrones, no sobre discriminación real entre clases.
- La curva ROC con el target de pedido refleja la dificultad real del problema: sin la inflación por repetición, el modelo tiene que trabajar con la señal genuina del dataset.
- La diferencia entre ambos AUC aísla el impacto exclusivo del error de granularidad: los puntos de AUC que se pierden representan aprendizaje que era espurio desde el origen.
- En la granularidad de línea,
LineRevenueacapara el 81% de la importancia: el modelo aprende que el ingreso de la línea predice casi perfectamente si esa línea pertenece a la clase objetivo, pero esa relación es una consecuencia directa de cómo se construyó el target, no una señal de negocio genuina. - Al agregar a nivel pedido,
LineRevenuedesaparece y la importancia se distribuye entremean_qty,mean_price,unique_productsyn_lines: el modelo debe trabajar con características del comportamiento real del cliente en lugar de aprender un artefacto de construcción. - La feature resaltada en cada gráfico (
n_linesen línea,unique_productsen pedido) delata la fuga: son proxies que el modelo habría podido explotar para reconstruir el target incorrecto, y su peso relativo cambia radicalmente al corregir la granularidad.
CódigoRepositorio del experimento
El notebook completo incluye la construcción de ambos targets, el pipeline de diagnóstico de granularidad, la comparación de métricas en los dos escenarios y las 8 visualizaciones.
- Dataset: Online Retail — UCI ML Repository — público, sin registro. Tienda británica de regalos 2010–2011 con 541,909 filas transaccionales a nivel de línea de producto.
- Target incorrecto:
high_value_line— ¿esta línea de producto supera la mediana de ingreso por línea? El problema: un pedido grande repite su señal 50+ veces en el entrenamiento. - Target correcto:
high_value_order— ¿este pedido supera la mediana de ingreso por pedido? Cada pedido aparece exactamente una vez. El modelo aprende características reales. - Detección: coeficiente de variación del número de líneas por pedido, importancia de features y comparación de AUC entre ambos targets.
- Modelos: Regresión Logística (coeficientes interpretables) y Random Forest (importancia de features) con los mismos hiperparámetros en ambos escenarios.
- Visualizaciones: distribución de líneas por pedido, clases por nivel de análisis, scatter ingreso–líneas, ingreso por clase, heatmap de correlaciones, Precision CV, curvas ROC e importancia de features.